






Όταν η Google έφερε την φωνητική αναζήτηση και στην εφαρμογή για το iOS, όσοι είχαμε iPhone και δοκιμάζαμε για πρώτη φορά την υπηρεσία εντυπωσιαστήκαμε από την αποτελεσματικότητά της στην αναγνώριση της φωνής μας. Πώς όμως καταφέρνει η εταιρεία να πετύχει ένα τόσο καλό αποτέλεσμα, που μοιάζει να μαντεύει από πριν τί είναι αυτό που θέλουμε να πούμε;
Η απάντηση έρχεται από την ίδια τη Google, που σε μια 7σέλιδη αναφορά εξηγεί πως ένας από τους παράγοντες που βελτιώνουν την υπηρεσία αφορά την αξιοποίηση των καθημερινών μας (γραπτών) αναζητήσεων, χάρη στις οποίες η φωνητική αναζήτηση μπορεί να κάνει αυτό ακριβώς: να μαντεύει αυτό που θα πούμε στη συνέχεια.
Πιο συγκεκριμένα, τα πάντα περιστρέφονται γύρω από τα δεδομένα. Όσο πιο πολλά είναι τα δεδομένα με τα οποία τροφοδοτείς μια διαδικτυακή εφαρμογή, τόσο πιο αποτελεσματική την κάνεις. Ειδικά στην περίπτωση της αναγνώρισης ομιλίας, σημαντικό ρόλο παίζει επίσης και ο τρόπος με τον οποίο οργανώνονται αυτά τα δεδομένα, όπου η εταιρεία αξιοποιεί τις λέξεις-κλειδιά που εισάγουμε στο google.com για να καταλάβει τί ακριβώς είναι αυτό που ψάχνουμε.
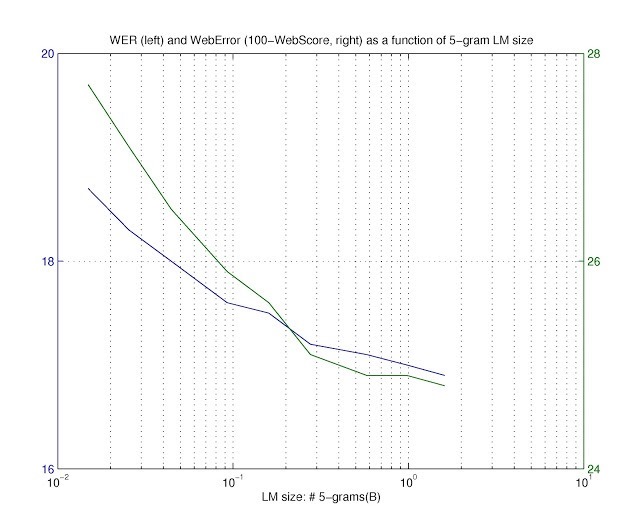
Όπως εξηγεί ο Ciprian Chelba της Google, το γλωσσικό μοντέλο είναι το στοιχείο εκείνο σε μια εφαρμογή αναγνώρισης ομιλίας που παίρνοντας τις προηγούμενες λέξεις μιας πρότασης, προσδίδει έναν βαθμό πιθανότητας για την επόμενη λέξη που θα ακολουθήσει. Προφανώς, όσο περισσότερα είναι τα δεδομένα με τα οποία θα τροφοδοτηθεί, τόσο πιο «έξυπνο» θα γίνει ως προς τις προβλέψεις του.
Για την βελτίωση της φωνητικής αναζήτησης, οι ερευνητές χρησιμοποίησαν γύρω στις 230 εκατομμύρια λέξεις από ένα τυχαίο δείγμα ανώνυμων αναζητήσεων στο google.com που δεν είχαν λάθη και δεν χρειάστηκε να ενεργοποιήσουν τον μηχανισμό ορθογραφικού ελέγχου. Σύμφωνα με τον Chelba, ένας τόσο μεγάλος όγκος δεδομένων μπορεί να μειώσει το ποσοστό λαθών στην αναγνώριση των λέξεων κατά 6%-10%. Εάν το εύρος των υπηρεσιών που τροφοδοτούν με δεδομένα μεγαλώσει, το ποσοστό σφαλμάτων μπορεί να μειωθεί ακόμη περισσότερο, κυμαινόμενο μεταξύ 17% με 52%.
Πηγη









0 σχόλια:
Δημοσίευση σχολίου